I recently returned from a week in the beautiful city of Zurich, attending a course on Bayesian Population Analyses. The course was organised by Marc Kery & Michael Schaub, and covers all the material in their book of the same name. This marks the culmination of a personal journey spanning more than 12 years. Looking back, I can see several distinct phases along the way (figure 1).
The first phase was characterised by fear and loathing. The fear was all about the unknown. Loathing is perhaps a harsh term to describe how I felt back in 2001, but I certainly had some fairly negative feelings. It was my first international conference and Bayesian methods for phylogenetic tree construction was a hot topic. Hot also describes the room in which the session was held. And packed. When Jo Felsenstein, a demigod of evolutionary biology, stood up to express his reservations I listened keenly without understanding the details (which are laid out in Chapter 18 of his 2004 book). But what really put me off was when a 'speaker' stood with back to audience, waving his arms at equations scrawled onto the overhead projector and mumbling softly. I really felt like I'd walked into a cult. Suffice to say that I was not persuaded.
The first phase was characterised by fear and loathing. The fear was all about the unknown. Loathing is perhaps a harsh term to describe how I felt back in 2001, but I certainly had some fairly negative feelings. It was my first international conference and Bayesian methods for phylogenetic tree construction was a hot topic. Hot also describes the room in which the session was held. And packed. When Jo Felsenstein, a demigod of evolutionary biology, stood up to express his reservations I listened keenly without understanding the details (which are laid out in Chapter 18 of his 2004 book). But what really put me off was when a 'speaker' stood with back to audience, waving his arms at equations scrawled onto the overhead projector and mumbling softly. I really felt like I'd walked into a cult. Suffice to say that I was not persuaded.
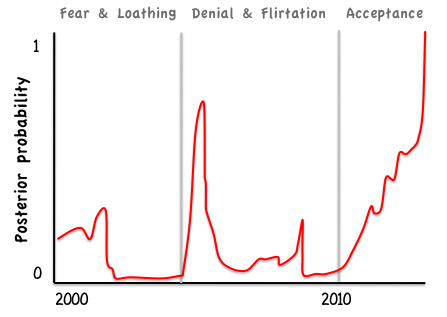
Figure 1: Probability that I would recommend Bayesian statistics to a colleague (credible intervals not shown)
There followed a lengthy period of denial, which was interspersed with occasional flirtation with black box type implementations of MCMC algorithms. I used the MLWiN software for one (much overlooked) paper, then returned to the safety of frequentist methods once it became easy to fit models with crossed random effects using lme4. I also tried the MCMC sampler to get p-values on model estimates from lme4: this fabulous tool, now defunct, was a strange chimera of Bayesian and Frequentist paradigms.
The real conversion started when I started working with citizen science datasets, and realised that Occupancy models could be the perfect solution. Occupancy models can be fitted using frequentist techniques in MARK or PRESENCE, but really struggle with the sort of large unstructured dataset that I work with, which contain many forms of sampling bias (see here for some examples). I found a like-minded collaborator in Arco van Strien, who has patiently persuaded me that Bayesian Occupancy models have the flexibility to model these biases explicitly (see this paper for a recent example).
Then I started reading 'Signal and the Noise', which includes many real-world examples of Bayesian reasoning. The author, Nate Silver, argues that success of any statistical model depends on having a good conceptual model of how the data are generated. As a macroecologist I have always been acutely aware of the distance between observations in my data and the biological processes that I'm interested in. Each time I conduct an analysis, I construct a mental picture of how biology and observations are linked, via a series of assumptions and approximations, some more explicit than others. In a classical statistics, all these simplifying steps get squished into a single error term: we're often forced to simply cross our fingers and hope that the biases cancel out. A hierarchical Bayesian framework allows these approximations to be expressed explicitly in a manner that is elegant and logical. The BUGS language also makes hierarchical models almost infinitely flexible. Rasmuth Baath has made the analogy with kids toys: if traditional statistics are like Playmobil then Bayesian analysis is like Lego.
By early 2014 I was ready for a complete conversion. The course was intense but enjoyable and to be recommended. I got fit my first Occupancy model and learned that sources of my initial fear (the complexity of MCMC, how to specify priors) are really not worth losing sleep over. I look forward to exploring the variety of different ways of implementing Bayesian models in R. Whilst I have been convinced about the value of Bayesian models, they remain slow to fit and the techniques for multimodel inference are poorly developed. Until these issues have been resolved I'll continue to hedge my bets from a philosophical perspective, flit between paradigms when it suite me. Bayes is just another tool in my analytical workshop, albeit a very shiny one.
The real conversion started when I started working with citizen science datasets, and realised that Occupancy models could be the perfect solution. Occupancy models can be fitted using frequentist techniques in MARK or PRESENCE, but really struggle with the sort of large unstructured dataset that I work with, which contain many forms of sampling bias (see here for some examples). I found a like-minded collaborator in Arco van Strien, who has patiently persuaded me that Bayesian Occupancy models have the flexibility to model these biases explicitly (see this paper for a recent example).
Then I started reading 'Signal and the Noise', which includes many real-world examples of Bayesian reasoning. The author, Nate Silver, argues that success of any statistical model depends on having a good conceptual model of how the data are generated. As a macroecologist I have always been acutely aware of the distance between observations in my data and the biological processes that I'm interested in. Each time I conduct an analysis, I construct a mental picture of how biology and observations are linked, via a series of assumptions and approximations, some more explicit than others. In a classical statistics, all these simplifying steps get squished into a single error term: we're often forced to simply cross our fingers and hope that the biases cancel out. A hierarchical Bayesian framework allows these approximations to be expressed explicitly in a manner that is elegant and logical. The BUGS language also makes hierarchical models almost infinitely flexible. Rasmuth Baath has made the analogy with kids toys: if traditional statistics are like Playmobil then Bayesian analysis is like Lego.
By early 2014 I was ready for a complete conversion. The course was intense but enjoyable and to be recommended. I got fit my first Occupancy model and learned that sources of my initial fear (the complexity of MCMC, how to specify priors) are really not worth losing sleep over. I look forward to exploring the variety of different ways of implementing Bayesian models in R. Whilst I have been convinced about the value of Bayesian models, they remain slow to fit and the techniques for multimodel inference are poorly developed. Until these issues have been resolved I'll continue to hedge my bets from a philosophical perspective, flit between paradigms when it suite me. Bayes is just another tool in my analytical workshop, albeit a very shiny one.
 RSS Feed
RSS Feed
